RLHF is a post-training pipeline that takes a pretrained “base” LLM and makes it behave more like human-labelers by:
- supervised fine-tuning on expert demonstrations,
- learning a reward model from human preference comparisons, and
- optimizing a policy with reinforcement learning (often PPO) to maximize that learned reward.
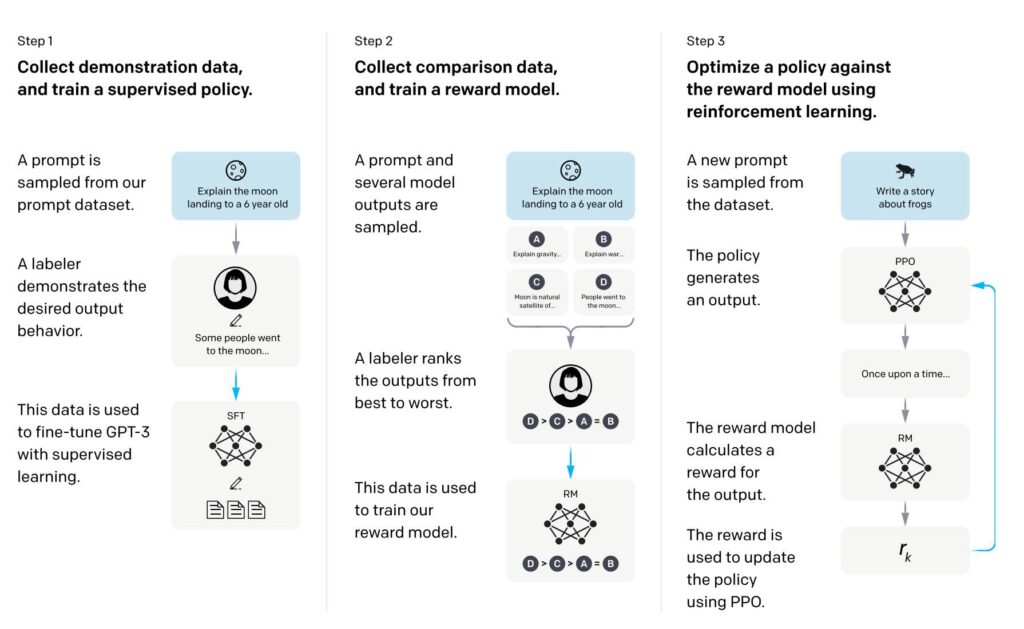
Mental model
I find it useful to name the key model instances, flowing as FM1 → FM1++ → RM → Policy.
- FM1: the starting foundation model (base LLM).
- FM1++: FM1 after SFT (supervised fine-tuning) on high-quality demonstrations.
- FM2: a separate reward model trained to score outputs the way expert humans would.
- FM3: a policy model optimized via RL to generate outputs that maximize the reward model. This FM3 is initialized from FM1++ (the same weights continue training)
General RLHF steps
- Step 1: From demonstrations → SFT.
- Sample from the prompt distribution of the ‘task’ you care about, like Q&A, summarize, reasoning, etc. Ask human expert labelers to write ideal answers in a rubric (let’s call it dataset A).
- Fine-tune FM1 with supervised learning on dataset A so the model imitates these “gold” answers. The result is FM1++ which is a strong baseline. Because this needs human experts, it is expensive, non-scalable, and with imperfect coverage. But it gives you a stable, “proven-safe-ish” starting point.
- Step 2: From preferences → reward model (RM).
- For each prompt, ask FM1++ to generate multiple candidate answers.
- Have labelers do pairwise comparisons (or rankings) based on the rubric. This produces dataset B: prompt, candidate A,B, etc… and which one is better.
- Train a separate model (FM2) to output a score that matches those preferences. Conceptually: the RM becomes a learned proxy for “how the labelers would rate this answer.”
- Step 3: Doing RL optimization of the policy.
- Initialize FM3 from FM1++ (common) so it starts near a sensible baseline. Sample prompts, get it to generate answers.
- Score those answers with the reward model (FM2). Let FM3 learn to increase expected reward.
Net effect: instead of only learning to imitate a limited demonstration dataset (Step 1), the model learns from human preferences over many model-generated candidates (Step 2), and then learns to generate what scores best under that preference model (Step 3).
In practice these are usually iterative: you repeat (collect preferences → retrain FM2 → re-optimize FM3) as you discover new failure modes and edge cases.
Other notes:
- Besides bespoke human demonstrations, we can also fine-tune on curated, higher-trust sources (e.g., government sites, UN docs, Wikipedia, scientific papers). None of this is guaranteed safe though—safety comes from dataset curation + filtering + a clear labeling/rubric policy, not the domain name.
- My intuition is that the biggest problem with RLHF is that it is a very downstream attempt to correct a model’s behavior – Model has already abstracted its main internals during pretraining and RLHF is after-the-fact nudging and calibration. The broad capabilities learned during pretraining often remain to some degree; RLHF can suppress or reshape how they’re expressed, but it doesn’t reliably “delete” capabilities—so with enough distribution shift / adversarial prompting, some behaviors can reappear. Which is why I feel like jailbreaking is one of the biggest issues with RLHF.
- Another problem is reward hacking: FM2 is only a learned proxy for human preference. When FM3 is optimized against FM2, it can learn to exploit FM2’s blind spots (Goodhart’s Law). This is why RLHF usually is done as an iterative loop: train RM → RL policy → find failures → collect more comparisons → retrain.
- Step 1 demonstration data is inherently limited; Step 2 expands coverage via comparisons, but there is still room for RL updates to be high-variance and “go weird” (unpredictable failure modes).
Resources
PRIMARY
- Ouyang et al. (2022). Training language models to follow instructions with human feedback (InstructGPT).