June’26 Update: After writing this post, I ended up making a live list of foundation models at pallavsharda.com/hcls-fm-map
Over the last few months, I’ve been exploring where AI foundation models are surfacing across healthcare and life sciences. I found some community-curated lists (example one, two) but they tend to organize by model architecture and not by data or domain, so I keep getting lost. What follows is my working landscape map. I’ve organized it into three areas: biology, chemistry, and clinical. Within each area, I’ve grouped the subcategories that seem most important today, along with representative models and organizations worth watching. The boundaries below are not a claim that things have already settled. A few categories could reasonably shift depending on whether you prioritize data modality, use case, commercial adoption, or scientific maturity. Also, the examples are meant to be illustrative. I named the ones where there was enough activity and organizational commitment that the category felt real. I’ll be making a more comprehensive list soon.
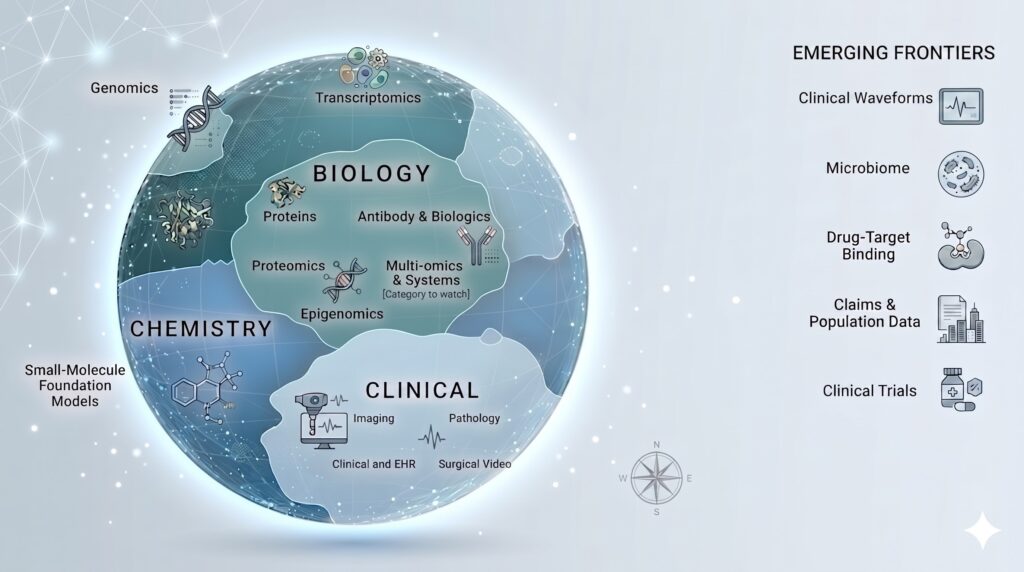
Area 1. Biology
The first area is foundation models that read or generate biological sequences and cellular state. These models take underlying representations of biology as input for their training: DNA, RNA, proteins, epigenetic marks, antibody sequences and increasingly, whole-cell state. It seems like this is where foundation models have moved fastest from research artifacts into practical R&D workflows. It is also where some of the most interesting interpretability work is beginning to land.
1.1 Genomics models
These foundation models process DNA sequence and learn regulatory patterns, evolutionary constraints, and sequence-function relationships that are not always explicitly annotated in the training data. They are useful for variant interpretation, regulatory genomics, synthetic biology, target discovery, and, eventually, more context-aware clinical genomics. The leading edge here is not just “read a gene, predict a protein.” It is learning how long stretches of sequence influence outcomes like expression, splicing, disease-relevant variation, etc. Representative models and efforts:
- Evo 2 (public since 2025) from the Arc Institute is designed to process long genomic context at nucleotide resolution.
- AlphaGenome (public since 2025) from Google DeepMind is focused on regulatory variant-effect prediction across modalities like expression, splicing, chromatin, and contact maps.
- Enformer (public since 2021), also from DeepMind and collaborators, an important earlier model for predicting gene expression from sequence by integrating long-range regulatory interactions.
- HyenaDNA (public since 2023), explores long-context genomic sequence modeling with architectures designed to scale beyond standard attention.
- Nucleotide Transformer (public since 2023) from InstaDeep and collaborators, is trained across species. Note: These models are powerful research substrates, but “variant-effect prediction” is not the same as validated clinical decision support. The strongest claim today is that they can help prioritize hypotheses and interpret regulatory biology, not that they replace functional assays or clinical genetics workflows.
1.2 Transcriptomics models
Transcriptomics models learn from RNA expression profiles, especially single-cell RNA-seq data. Their goal is to represent cell states, gene co-expression patterns, perturbation responses and regulatory relationships. This category matters because single-cell biology is where many drug-discovery questions are becoming more concrete: Which cell state matters? Which pathway is active? Which change shifts the system toward or away from disease? Representative models and efforts:
- Geneformer (public since 2023) is trained on large-scale single-cell transcriptomes.
- scGPT (public since 2023) is for single-cell and multi-omics analysis.
- TranscriptFormer (public since 2025) from the Chan Zuckerberg Initiative, a cross-species generative model.
- Arc’s virtual-cell work, including State (public since 2025) and Stack (public since 2026), is pushing towards perturbation prediction and in-context learning over cellular conditions. This is one of the categories where the boundary could easily be drawn differently. You could call this “transcriptomics,” “single-cell foundation models,” or “virtual cell models.” I am grouping them together because, from an adoption lens, the shared question is whether we can learn reusable representations of cell state.
1.3 Protein models
Protein foundation models are probably the most visible success story in AI for biology. They predict or generate representations over protein sequence, structure, and function, and newer systems increasingly reason over biomolecular complexes rather than isolated proteins. Models like AlphaFold have transformed structure prediction. Note that this does not mean we have solved protein design, binding, stability, or in vivo behavior. Representative models and efforts:
- AlphaFold 3 (public since 2024) from Google DeepMind and Isomorphic Labs focuses on predicting structures of biomolecular complexes.
- ESM3 (public since 2024) from EvolutionaryScale is a multimodal model over protein sequence, structure, and function.
- RoseTTAFold All-Atom (public since 2024) from the Baker Lab is extending structure prediction and design toward broader biomolecular assemblies.
- OpenFold3 (public since 2025) is an open-source effort to support reproducible biomolecular co-folding models. PrimateAI-3D (public since 2023) from Illumina sits at the boundary of genomics and proteomics because it uses protein structure and primate variation to score missense variant pathogenicity. I would treat it as a bridge. It can be closer to genomics (if organized by input data) or proteins (if organized by biological mechanism).
1.4 Epigenomics models
Epigenomic models look at methylation, chromatin accessibility, cfDNA fragmentation, and other signals that describe how DNA is regulated or packaged rather than what the DNA sequence is (i.e. Genomics models). I find this category especially interesting (and actionable!) because it can detect disease-relevant signal even when the underlying genome sequence is unchanged. This category feels real, but younger. One representative effort is Pleiades (public since 2025) from Prima Mente, currently focused on cfDNA and Alzheimer’s biomarker discovery. This category doesn’t seem to have the same public benchmark clarity or community convergence as protein structure prediction or single-cell transcriptomics.
1.5 Antibody and biologics models
Antibody-specific language models learn the statistical grammar of antibody sequences and immune patterns. This is a specialized but important subcategory because biologics drug development has always been highly iterative. A reusable model of antibody sequence space can, at minimum, help researchers explore more efficiently. Representative models:
- IgLM (public since 2022) is a generative antibody language model from the Gray Lab ecosystem.
- AbLang2 (public since 2024) is an antibody-specific language model from the Oxford Protein Informatics Group.
- AntiBERTy (public since 2021) was the antibody language model that helped establish the category. I kept this category separate from general protein models because here the question is not only structure or function; it is whether the sequence is human-like, stable and manufacturable.
1.6 Multi-omics and systems models
These try to integrate transcriptomics, genomics, proteomics, epigenomics, imaging, and sometimes clinical context into a more unified representation of disease biology. Impact evidence is uneven but the aspiration is obvious. For example, drug discovery and translational research need pathway-level evidence, not isolated signals from a single modality. The hard part is that multi-omics data tend to be noisy and often proprietary. For now, I’m treating multi-omics and systems models as a category to watch, with no prominent models. I just think the category is still less settled than others.
Area 2. Chemistry
The second area is foundation models for molecular structure and chemical language. These models learn representations of molecules where distance in latent space can correspond to chemical or pharmacological properties: potency, solubility, toxicity, etc. When I first learned about these models, they felt like a fascinating extension of the LLM idea: moving beyond vector representations of English words to vector representations of molecules.
This category matters because it sits directly inside the actionable part of drug discovery. The models can be used to generate candidates, optimize properties, search chemical space, and move downstream to screening. Chemical foundation models typically operate over learned molecular representations. They are the workhorses of AI-assisted medicinal chemistry and many production systems look proprietary. Representative models and platforms:
- MolMIM (public since 2024) from NVIDIA BioNeMo focuses on controlled molecule generation with property guidance.
- MoLFormer (public since 2022) from IBM Research and collaborators is a large-scale chemical language model over molecular representations.
- MegaMolBART (public since 2021) is another NVIDIA model in the BioNeMo family.
- ChemGPT (public since 2022) is an early example of generative chemical language modeling. The main caveat here is that “small-molecule foundation model” can mean several things: a general molecular representation model, a molecule generator, a property predictor, or a component inside a closed-loop discovery platform. I could imagine this area splitting further over time if reaction prediction, assay-aware models, or larger biomolecular design systems become more visible as distinct categories.
Area 3. Clinical
These models touch clinical data directly and I expect the adoption threshold to be highest here. The closer a model gets to patient care, the more we should care about validation, failure modes, monitoring, workflow fit, and liability. A model may be scientifically impressive and still not be ready for clinical deployment.
3.1 Medical imaging models
Radiology-specific models can support detection, triage, retrieval, report generation, visual question answering, and multimodal reasoning. I’m intentionally separating radiology from pathology even though both are visual. They have different data structures, workflows, regulatory histories, and adoption paths. Representative models and efforts:
- Med-Gemini (public since 2024) from Google Research have been evaluated across text, image, video, and EHR-like tasks.
- BiomedCLIP (public since 2023) from Microsoft and collaborators is a biomedical vision-language model trained on PubMed image-text pairs.
- CXR Foundation (public since 2023) from Google is focused on chest X-ray representation learning.
- RadFM (public since 2023) is a generalist radiology foundation model.
3.2 Digital pathology models
Pathology foundation models learn representations from whole-slide images and can support tumor detection, classification, survival prediction, etc. They have the potential to surface image-derived signals that may not be obvious to human review. Representative models and efforts:
- Virchow (public since 2023) from Paige is trained for cancer pathology.
- Prov-GigaPath (public since 2024) from Microsoft Research and Providence is a gigapixel pathology foundation model using tile-to-slide representations.
- UNI (public since 2024) from the Mahmood Lab is a general-purpose pathology foundation model.
- CONCH (public since 2023) is also built by the Mahmood Lab and focuses on pathology vision-language alignment. Pathology is one of the clearest clinical categories because the data modality is specialized, high-fidelity and tied to well-defined downstream tasks. The key question in my mind is which use cases survive workflow integration and monetization.
3.3 Clinical and EHR language models
This category of models operates over messy, longitudinal frontline-care data: provider notes, lab orders and results, procedure notes, referrals, medications, claims, and more. They typically support use cases of summarization, population health (cohort selection, risk prediction, etc) coding, documentation, and clinical reasoning.
This category needs careful classification. Some are research systems, some are enterprise products, others are tuned general LLMs. Some are trained directly on EHR data, others not. Those are not all the same thing. Representative models and efforts:
- Truveta Language Model (public since 2023) from Truveta is a prominent effort trained on a large linked EHR corpus with emphasis on longitudinal patient data.
- GatorTron (public since 2022) from the University of Florida and NVIDIA is trained on clinical text.
- NYUTron (public since 2023) from NYU Langone has been evaluated for in-hospital predictive tasks.
- CLMBR (public since 2021) from the Stanford Shah Lab ecosystem models over EHR timelines.
- Med-PaLM (public since 2022) and MedLM (public since 2023) from Google sit closer to medical question-answering than just EHR-based pretraining.
- AMIE (public since 2024) from Google Research is a research system for diagnostic dialogue. I’m keeping EHR models, medical question-answering models, and diagnostic-dialogue systems in the same neighborhood, but not collapsing them into one bucket. They share clinical language, but differ in data, validation, and workflow.
3.4 Surgical and endoscopy video
I was surprised to find video foundation models trained on temporal representations from procedural video data. They can be useful for phase recognition, instrument tracking, quality assessment, and skill evaluation. This category feels like a younger sibling of radiology and pathology. It is not just ordinary computer vision applied to video; there is credible potential for foundation-model learning from procedural data. Representative models and efforts:
- SurgVISTA (public since 2025) is a surgical-video foundation model effort for intelligent surgery tasks.
- Endo-FM (public since 2023) from CUHK and collaborators is an endoscopy foundation model with video pretraining.
Categories just starting to land
The three areas above are what I would defend today as having enough credible foundation-model activity to deserve a visible place on the map. Below the line are categories where foundation-model work exists, but I have not yet seen either a category-defining model or enough public adoption.
- Clinical waveforms: ECG, PPG, EEG. Specialized models such as HeartBEiT (public since 2022) for ECG and LaBraM (public since 2024) for EEG suggest real movement. Wearable-signal foundation models are also starting to appear, especially around ECG and PPG.
- Microbiome and metagenomics. This is emerging quickly with work like METAGENE-1 (public since 2025). It may deserve a main category soon.
- Drug-target interaction and binding affinity. This overlaps with protein modeling, small-molecule modeling. One could reasonably argue that it deserves its own category. My current view is that it is better treated as a cross-cutting task.
- Claims, public-health, and population-level data. The data are massive and important, but I haven’t seen much public, category-defining foundation-model activity here. Given the lack of incentives for sharing data across entities, I doubt this will happen soon. Maybe federated learning can help (note OWKIN, Rhino).
- Clinical trials. There is strong commercial interest, but the foundation-model substrate is less clear than the workflow interest. If you think one of these belongs above the line, or that I am missing a category entirely, drop me a note. This is meant to be a map that improves with argument.
Why the map matters: AI safety
Every entry on this map has the same uncomfortable property: the model is being used, evaluated, or proposed for settings where mistakes can affect patients, therapies, diagnoses, or scientific decisions. That is why foundation models in healthcare and life sciences cannot be evaluated only by benchmark performance. The questions are broader:
- Can we tell what the model has learned?
- Can we distinguish a useful biological feature from a shortcut, artifact, or dataset bias?
- Can a stakeholder understand enough about the full system to trust it?
The early work I find most interesting is coming from efforts like Goodfire and Arc’s work around Evo 2, where sparse autoencoders are being used to decompose messy internal activations into more human-understandable features. Circuit tracing then asks how those features contribute to later features and, eventually, to outputs. I’ve been paying attention to interpretability for a while now.
I also think the broader AI-safety stack matters here: chain-of-thought monitoring, system cards, model evaluations, red-teaming, post-deployment monitoring, and explicit documentation of limitations. Together, these may be a start for the transparency layer that high-stakes deployments need.
The map will keep changing, but the underlying question will not: can we make these systems useful enough to matter, and transparent enough to trust?