
A transformer is the major breakthrough of recent times – a neural network architecture that uses attention to process all tokens in parallel instead of step-by-step like an RNN.
- Processes sequences in parallel
- Built from stacked blocks of attention + feedforward layers
- Scales very well with data and compute (better for long texts + GPUs/TPUs))
Why are they better
- RNNs have sequential bottleneck, long range dependencies
- CNNs only partially fix this
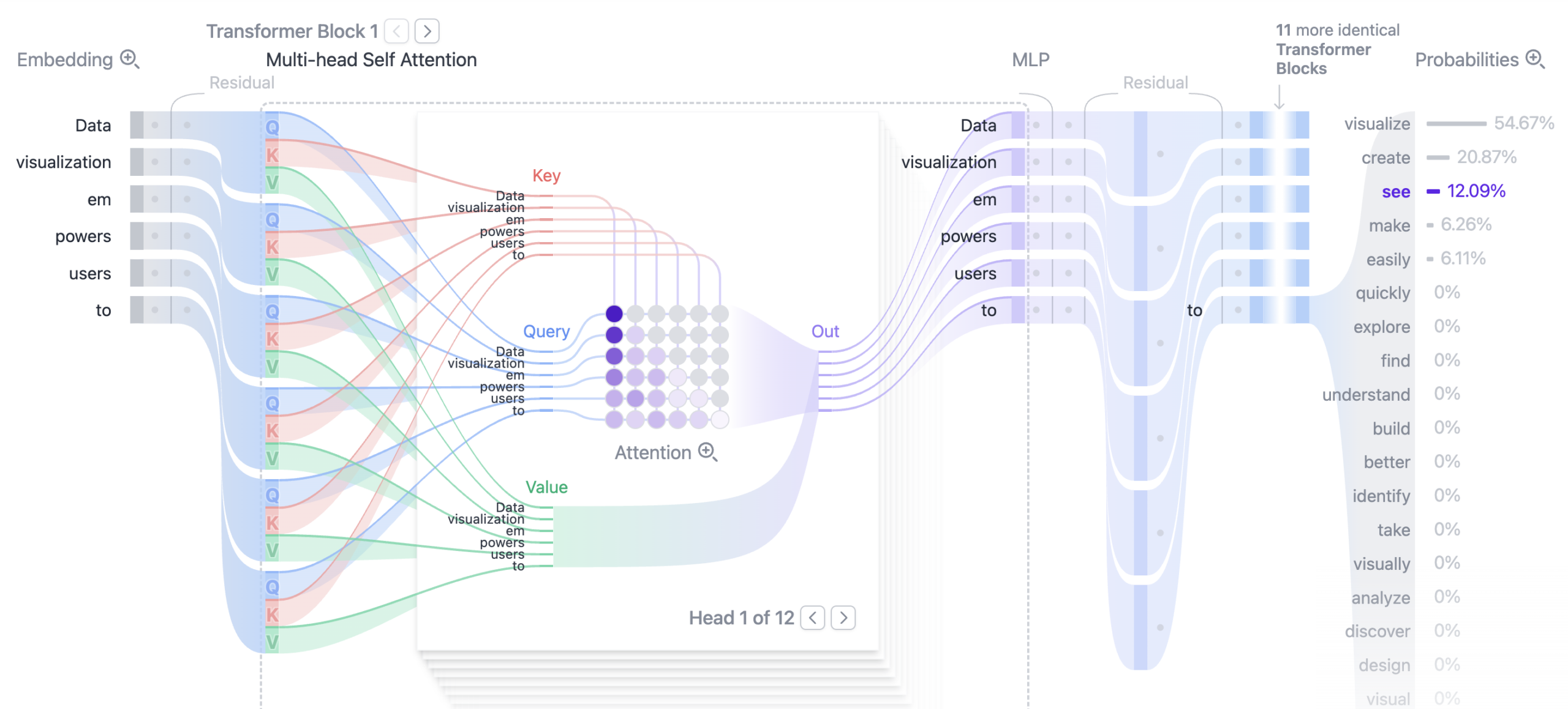
High level structure
- Embedding
- Encoder, Decoder
- Attention
Position-aware encoding: Have the vector embedding preserve the relative positions of data sequence. That positional embedding is repeated 3 times in the neural net:
- Query (Q)
- Key (K)
- Value (V)
Primary Resources
- Incredible interactive transformer explainer by poloclub.
- In Harvard CS50’s Introduction to Artificial Intelligence with Python 2023, Lecture 6, Brian Wu explains transformer architecture at 00:54:15