
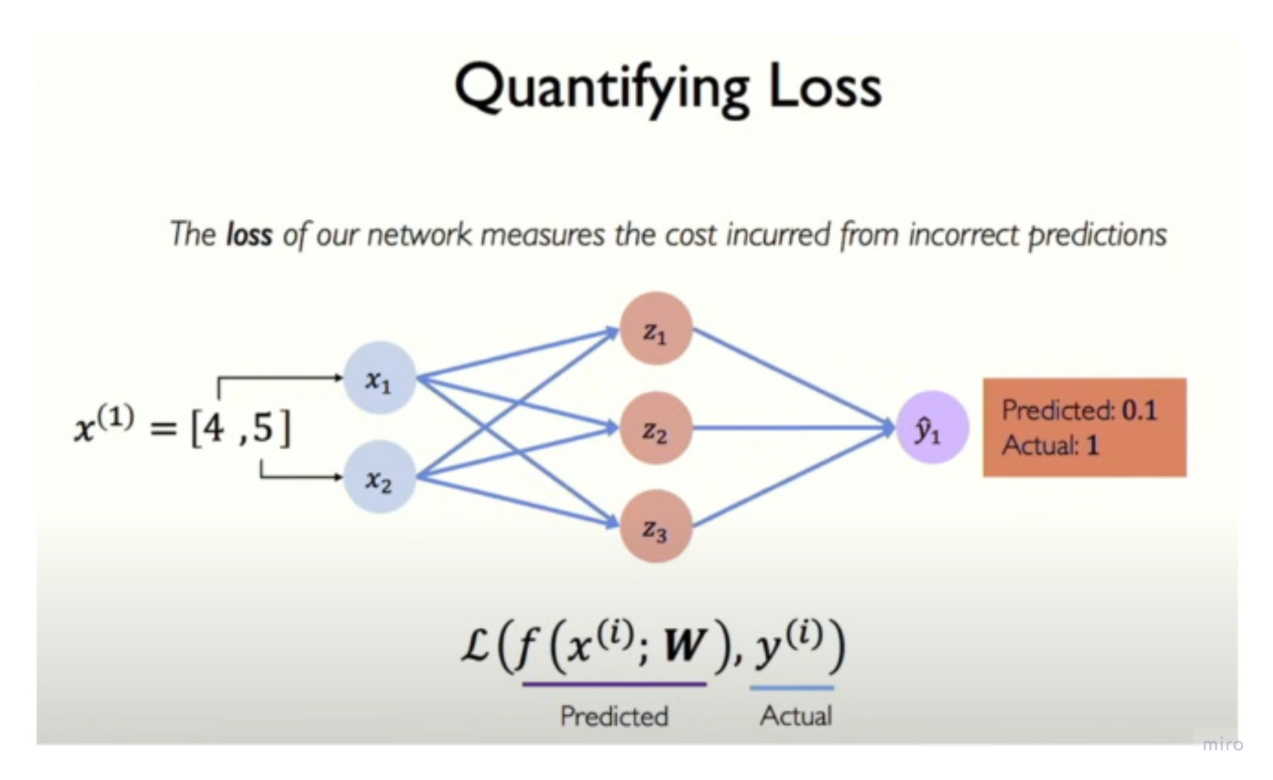
Given an input and its correct (target) output, a loss function compares the model’s prediction to the target and returns a single number measuring how wrong the prediction is.
- That number is called the Loss
- Larger loss means a worse prediction; zero loss means a perfect prediction.
Training a neural network means changing the parameters (weights and biases) to make this loss as small as possible on the training data.
- Since Loss is a mathematical function, we can use calculus to find it’s slope (gradient)
- That gradient tells us which direction to change the input parameters (weights, bias) such that the loss keeps decreasing. Doing that, is [[Gradient Descent]].
Complex stuff
- Parameters are the things the network learns during training (through backpropagation), based on the data given: ie. weights, biases.
- Hyperparameters are the settings that define the model architecture and training procedure (like learning rate, batch size, number of layers), which are chosen by the practitioner and not learned directly from the data.
- Note that for any given problem, one has to select an appropriate loss function. A popular one is square-of-error