
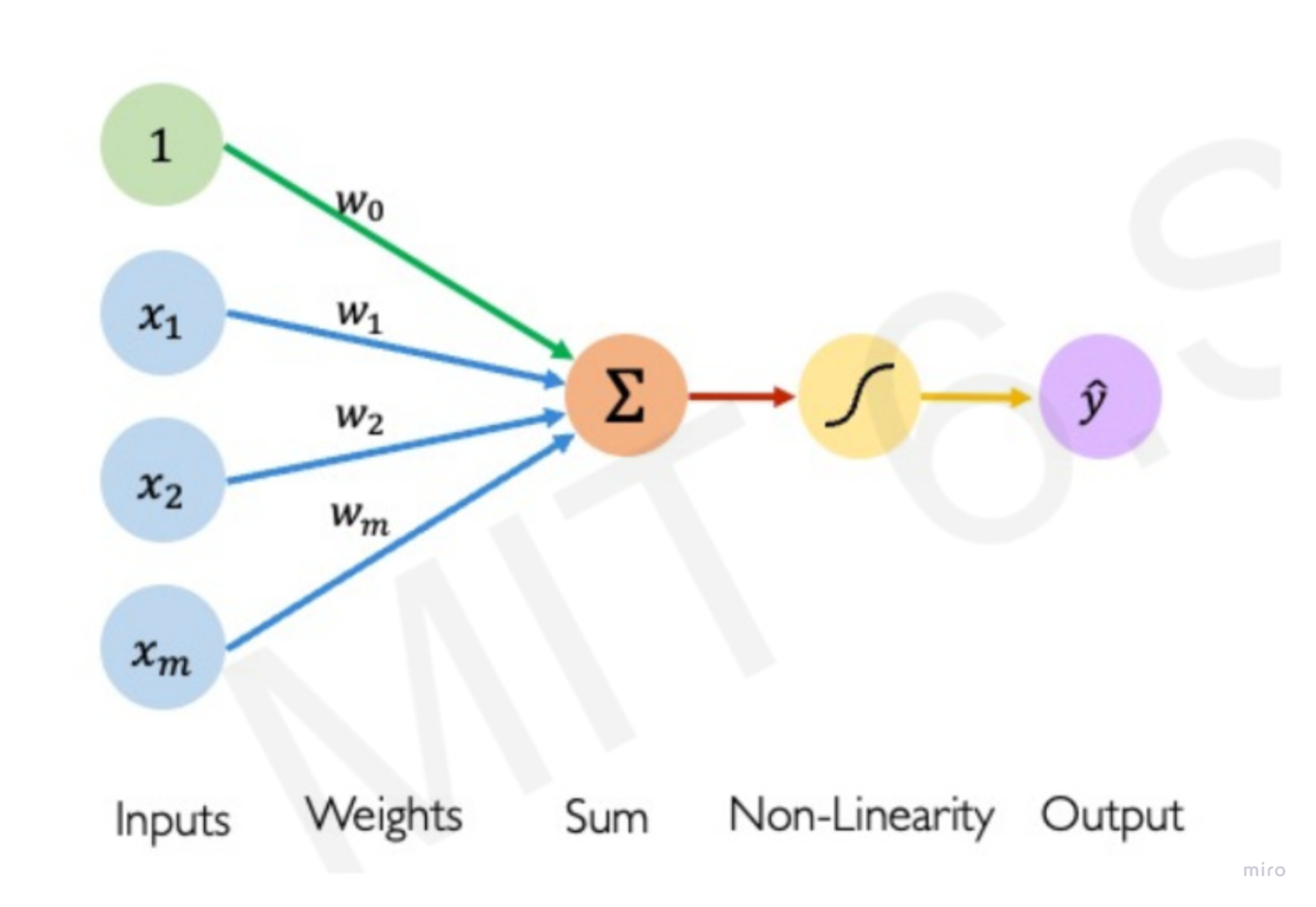
Perceptron = the simplest artificial neuron that takes multiple inputs, multiplies them by weights, adds a bias, and turns the result into a yes/no (or score) output.
- Inputs: a vector of features (x1,x2,…,xn)
- Parameters:
- One weight per input (w1,w2,…,wn)
- An overall bias (b) → sometimes written as w0 for a neutral input
- Computation: weighted sum
- Non-linearity (activation function) that determines the threshold after which output is generated. Most common is ReLU.
Intuition
- Think of a perceptron as a tiny yes/no rule that looks at several numeric input signals and then fires (1) or stays silent (0).
- Each weight is how much that input “votes” for firing (positive weight) or against (negative).
- The bias is how “easy” it is to fire even when inputs are small; it shifts the decision boundary.
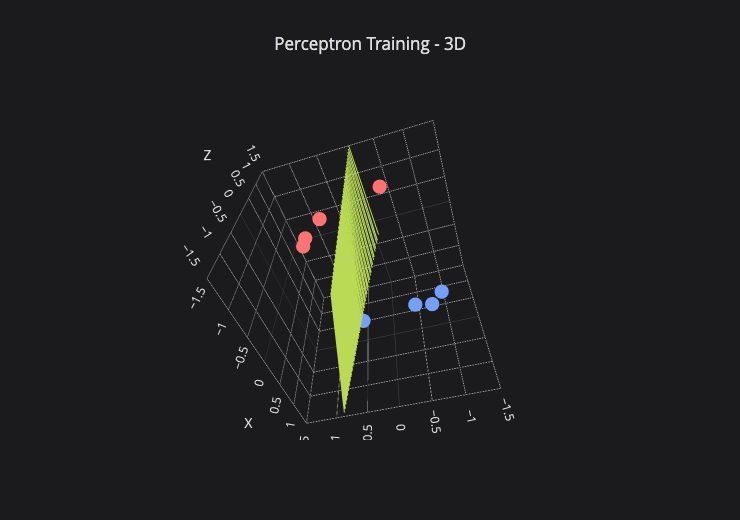
- In the simple case where there are only 2 input features, you can literally plot the input data points on a xy plane. Then the perceptron’s decision boundary is a straight line that splits them into ‘fire’ vs ‘don’t fire’ based on their combination of the two features.
- In 3D, it’ll be a flat plane. In higher dimensions, it’s the same idea but perceptron boundary is a (hyper)plane in n-dimensions. It is always carving the input space into two half-spaces (fire vs not fire).
- Just one perceptron on it’s own is a linear classifier. If the data needs a curved boundary or multiple disjoint regions (like XOR), a lone perceptron cannot represent it—that’s when we stack perceptrons to get non-linear decision boundaries (MLP or Multi-Layer Perceptrons). That’s what makes the layers of deep learning. See [[Layers]]
- ChatGPT (GPT 3.5) had 100M perceptrons
Complex Stuff
- There is mathematical proof of Perceptron Convergence theorem which states that If your data can be perfectly separated by a straight line, the perceptron algorithm is guaranteed to find some separating line
Primary Resources
- 3Blue1Brown – But what is a Neural Network?. The first 6ish minutes talks about neurons (perceptrons) and layers.
- The first 15ish minutes of Lecture 5, Harvard CS50’s Introduction to Artificial Intelligence with Python 2020 as a simple way to understand perceptrons and it naturally extends into layers and gradient descent concepts. It was my first intro to the basic building blocks of LLMs.
- Lecture 1: Introduction to Neural Networks and Deep Learning, Hands-On Deep Learning course by MIT OpenCourseWare. Prof. Rama Ramakrishnan delivers it well.
- Karthik Vedula has an interesting interactive explanation of the Perceptron Learning Algorithm
- I wrote a post comparing biological and artificial neurons, cross-walking their conceptual overlaps.